
Blockchain is NOT your database — hybrid design rules
Crucial system design architectures: ProofChain, Firebase caching, IPFS hashing, event indexing, and resolving query issues.
When I was building ProofChain — a proof-of-existence system where you can register a document on the blockchain and prove it hasn't been tampered with — I hit the wall instantly.
My first instinct: store everything on-chain. The document. The metadata. The owner. The timestamp. The filename.
I calculated the gas cost for storing a 50MB PDF on Ethereum.
$47,000 per upload.
I stared at that number for a full minute. Then I understood the fundamental rule that every enterprise Web3 architect eventually learns the hard way:
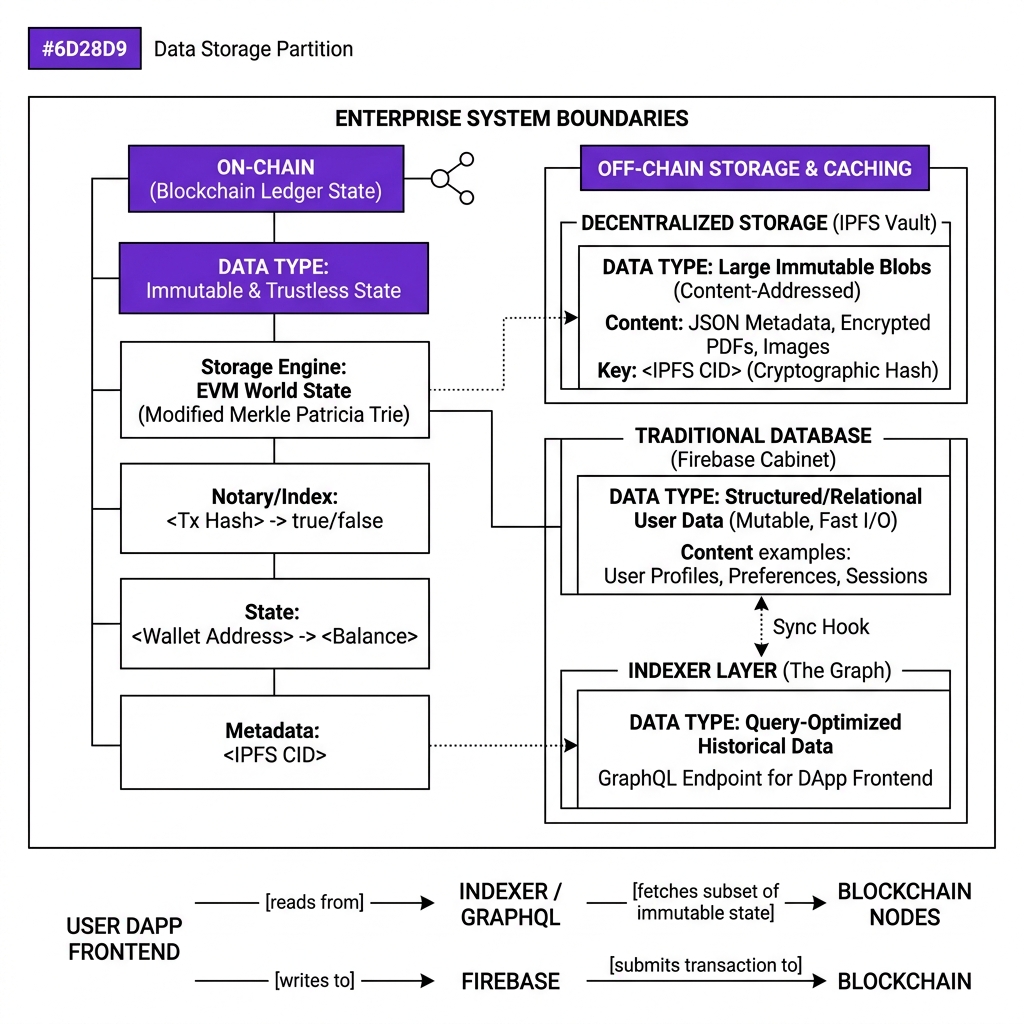
The blockchain is not your database. It's your notary.
1. The Core Principle: Defining the Trust Boundary
When modeling an enterprise system (like a decentralized pharmaceutical supply chain), you must inspect every data variable and ask:
- On-Chain Candidates: Token ownership mappings, cryptographic hashes of documents, supply chain state transitions, and authorization registries. These require consensus and absolute immutability.
- Off-Chain Candidates: User avatars, item descriptions, employee profile details, transaction history tables, and search indexes. These belong in standard databases or decentralized file stores.
"Fully decentralized" is a system design trap. Storing descriptive data on-chain is an anti-pattern that leads to gas bottlenecks and unusable user interfaces. You must design your system to store only the mathematical proof on-chain, caching all descriptive assets off-chain.
2. The Hybrid Enterprise Web3 Stack
A production-grade Web3 architecture separates execution, storage, and querying into three highly specialized layers:
- The Ledger Layer (Smart Contracts): Executes the state machine, verifies cryptographic signatures, and records proof hashes.
- The Decentralized File Layer (IPFS): Acts as a global, immutable hard drive. Larger files are uploaded here and referenced via their unique Content Identifier (CID) hash.
- The Indexing Layer (The Graph): Listens to contract events in real-time, processes transactions, and maintains a highly optimized GraphQL search index.
- The Cache Layer (Databases): Pulls pre-processed data from the indexing engine, serving instant search results (like fuzzy matching and chronological sorting) to the client UI.
During the launch of an early supply chain registry, the team attempted to query historical shipment details directly from RPC node logs on every dashboard page load. The RPC nodes rate-limited the server, causing the UI loading times to exceed 12 seconds. By migrating the query pipeline to a synced Subgraph cache layer, UI response times dropped to 80 milliseconds.
3. ProofChain: The Real Example
ProofChain is a proof-of-existence system. You upload a document. It proves it existed at a specific moment, unchanged, with a specific owner. Here is exactly how the hybrid architecture makes this possible:
If anyone alters a single pixel in the PDF sitting on IPFS, their recomputed hash will mismatch 0x9a8f... — the fingerprint permanently written to the chain. The tamper is immediately provable.
Notice what the blockchain stores: 32 bytes. Not the file. Not the metadata. Not the owner's name. Just the cryptographic fingerprint.
Notice what Firebase stores: everything humans actually need to browse and search.
Notice what The Graph indexes: the on-chain event history, so the frontend can query "all documents registered by this wallet" in milliseconds.
The blockchain is the notary. Firebase is the filing cabinet. IPFS is the vault.
Socio3 V2 Distributed Architecture
Click any component node in the hybrid stack blueprint below to dissect its system design, failures, and production solutions.
Always design a fallback path in your system. If the indexing engine experiences an outage, your frontend must fallback to querying the RPC node directly for essential trust validations, ensuring your core security is never compromised by cache failures.
Look at a decentralized protocol like OpenSea. When you search for "trending NFTs" and filter by "price: low to high," identify which layer of the hybrid stack is executing that sorting. Why is it mathematically impossible to run that query directly against an Ethereum node?
Was this lesson helpful?
Let us know what you think of this specification. (submitting anonymously)