
Why direct RPC queries die at scale
Socio3 V1 scaling autopsy: how loading feeds via JSON-RPC works at 10 posts, degrades at 1000, and freezes browsers at 10000.
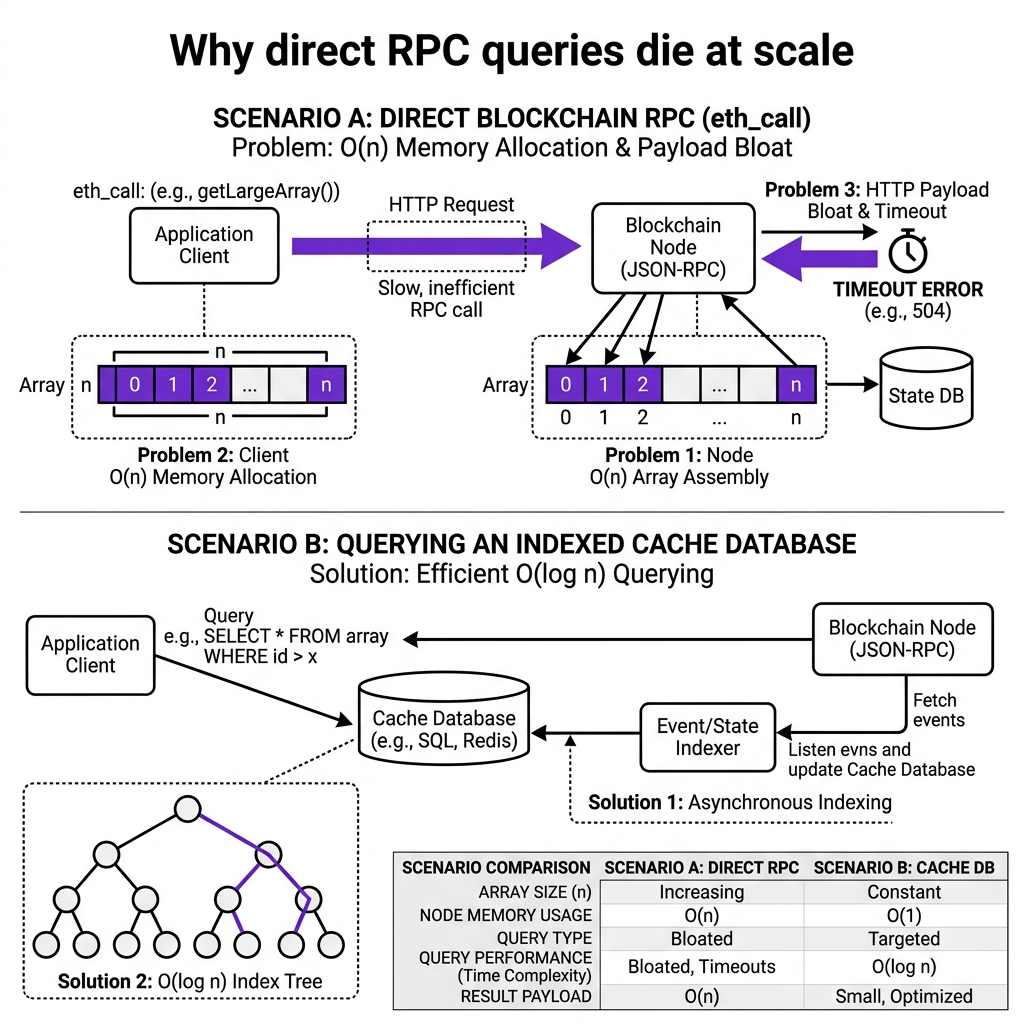
When I built Socio3 V1, I had a simple, naive plan to render the home feed:
- Load the page.
- Call
PostContract.getAllPosts()using an RPC provider (like Alchemy or QuickNode). - Sort and filter the results in JavaScript on the client.
- Render the posts.
At 10 posts, it loaded in 150ms. I thought it was production-grade. At 1,000 posts, the page took 4.5 seconds to load, blocking the main browser thread. At 10,000 posts, the RPC provider threw a timeout exception (code -32000) and the app completely died.
Here is the exact autopsy of why direct RPC queries are a death sentence for scalable Web3 systems.
1. The Anatomy of a JSON-RPC Call
When your React app talks to the blockchain, it uses the JSON-RPC protocol over HTTP/WebSockets.
To fetch post data, it calls eth_call:
An RPC node (like Alchemy) receives this payload, passes it to an archive node, runs it through an EVM execution sandbox, and returns the result.
This is fine for simple reads. It is catastrophic for query processing.
2. The O(n) Blockchain Bottleneck
Let's dissect what happens inside an archive node when you call getAllPosts():
To execute this view call, the EVM must:
- Locate the storage slots allocated for
allPosts. - Loop through every item, expanding the array dynamically in volatile EVM memory.
- Serialize the full dataset into a huge hexadecimal output string.
- Send the string over HTTP back to the client.
As n increases, memory allocation and serialization times grow linearly (O(n)). On a public RPC node, execution budgets are capped at 5–10 seconds. Once your array crosses the limit, the node aborts the sandbox and throws a timeout error.
3. The Network Cost of RPC Bloat
If allPosts contains 5,000 items, and each metadata CID string is ~100 bytes:
- The JSON-RPC response payload exceeds 1.5 Megabytes.
- The user's mobile browser must download, parse, and decode this hex string.
- In Web2, databases use pagination (
LIMIT 10 OFFSET 20) to prevent this bloat. - Solidity mappings have no native search indices. You cannot run
LIMITqueries on a mapping.
4. The RPC Rate Limit Wall
Public RPC nodes (and free-tier API endpoints) enforce strict rate-limiting policies based on Compute Units (CUs).
- A simple
eth_blockNumbercall costs ~10 CUs. - A massive
eth_calliterating through 1,000 storage slots costs 1,000+ CUs. - With just 50 concurrent users refreshing their feeds, your app will exhaust its daily Alchemy API limit in minutes, rendering the site unusable.
Solidity arrays are strictly for smart contract logic verification. They are NOT database tables. If your frontend depends on contract-level iteration to render lists of items, your dApp is not production-ready.
If you must read a small dataset directly from a contract without an indexer, how can you design a pagination flow? Hint: What if your Solidity contract accepts a startIndex and limit parameter, and how does the frontend coordinate this?
Was this lesson helpful?
Let us know what you think of this specification. (submitting anonymously)